Use your preferred visualization library to create a scatterplot showing petal length vs petal width. You should plot each flower species as a different color on the scatter plot.
Data preparation (sometimes called “data wrangling” or “data munging”) is where you’ll usually spend the bulk of your time when working on machine learning problems. Only rarely is data already in the optimal form for a given algorithm.
Often we have to deal with missing values, normalize the data, and perform both simple and complex feature engineering to get the data into the form we need.
Once the data is in the correct form, we can then randomize the data and split it into training and test datasets (and sometimes an additional validation dataset).
Machine Learning Steps
Almost universally, regardless of which algorithm or type of task we’re performing, building and evaluating a machine learning model with sklearn follows these steps:
Perform any data preprocessing needed.
Partition the data into features and targets.
Split the data into training and test sets (and sometimes a third validation set).
Create a configure whichever sklearn model object we’re using.
Train the model using its “fit” method.
Test the model using its “predict” method.
Use a model evaluation metric to see how well the model performs.
If the model isn’t performing well, we will repeat one or more of the above steps (sometimes all of them).
Once the model is performing adequately, we’ll deploy it for use as part of some larger system.
For now, let’s assume that this dataset is in the form we need, and we’ll skip to step 2, partitioning the data.
Step 2. Partition the Data into Features and Targets
First, we’ll create a dataframe called “X” containing the features of the data we want to use to make our predictions. In this case, that will be the sepal_length, sepal_width, petal_length, and petal_width features.
(The name “X” isn’t special, but uppercase X is the conventional name for our feature dataset, because that’s what statisticians use to refer to a matrix of independent variables)
# Create a new dataframe called X that contians the features we're going# to use to make predictionsle = LabelEncoder()iris['species_encoded'] = le.fit_transform(iris['species'])iris.species_encoded.unique()
array([0, 1, 2])
Next we’ll create a dataframe called “y” containing the target variable, or the set of values we want to predict. In this case, that will be species.
(Once again, the name “y” isn’t special, but lowercase y is the conventional name for a list of targets, because that’s what statisticians use to refer to a vector of dependent variables)
# Create a new dataframe called y that contians the target we're# trying to predictX = iris.drop(columns=['species', 'species_encoded'])Y = iris['species_encoded']X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=62)modelknn = KNeighborsClassifier(n_neighbors=3)
Step 3. Split the data into training and test sets.
Now that we have our data divided into features (X) and target values (y), we’ll split each of these into a training set and a test set.
We’ll use the training sets to “train” our model how to make predictions.
We’ll then use our test sets to test how well our model has learned from the training data.
While we could use a bunch of python code to do this step, the sklearn library has lots of built-in functions to handle common data manipulations related to machine learning.
# Import and use the train_test_split() function to split the X and y# dataframes into training and test sets.## The training data should contain 80% of the samples and# the test data should contain 20% of the samples.
After creating the training and test splits, output the head() of each one and notice how they row numbers have been randomized.
Also notice that X_train and y_train’s row numbers match up, as do X_test and y_test’s row numbers.
Part D: Create and Train a Model
We’re going to create a model based on the k-Nearest Neighbors algorithm.
Since this is a classification task, (we’re trying to classify which species a given flower belongs to), we’ll use sklearn’s KNeighborsClassifer.
Step 4. Create and configure the model
We start by importing the information about the model we want to create. In python, this information is called a class.
The KNeighborsClassifier class contains all of the information python needs to create a kNN Classifier.
Once we’ve imported the class, we’ll create an instance of the class using this syntax:
In our case, the class name is KNeighborsClassifer. It doesn’t matter what we call the variable that holds the instance, but one popular convention is to call classifier instances clf, so that’s what you’ll see in the sklearn documentation.
The only parameter we want to configure is the n_neighbors parameter, which controls the value of k in the kNN algorithm.
# Import the KNeighborsClassifier class from sklearn# Note that it's in the neighbors submodule. See the example code in the# documentation for details on how to import it
# Create an instance of the model, configuring it to use the 3 nearest neighbors# store the instance in a variable
Step 5: Train the model
Next we’ll train the model. We do this by providing it with the training data we split off from the dataset in step 3.
The model “learns” how to associate the feature values (X) with the targets (y). The exact process it uses to learn how to do this depends on which algorithm we’re using.
Sometimes, this is called “fitting the data to the model”, so in sklearn, we perform this step using the fit() method.
# Call the "fit" method of the classifier instance we created in step 4.# Pass it the X_train and y_train data so that it can learn to make predictionsmodelknn.fit(X_train,Y_train)YPred = modelknn.predict(X_test)
Part E: Make Predictions and Evaluate the Model
Now that the model has been created and trained, we can use it to make predictions. Since this is a classification model, when we give it a set of features, it tells us what the most likely target value is.
In this case, we tell the model “here are the values for petal width, petal length, sepal width, and sepal length for a particular flower” The model then tells us which species is the most likely for that flower.
When testing how well our model works, we’ll use the test data we split off earlier. It contains the measurements for several flowers, along with their species.
Step 6: Make Predictions on Test Data
We’ll give the measurements of each flower to the model and have it predict their species. We’ll then compare those predictions to the known values to determine how accurate our model is.
Since this is a classification model, there are two different methods we can use to make predictions:
predict(), which returns the most likely prediction for each sample.
predict_proba() which returns a list of probabilities for each sample. The probabilities tell us how confident the model is that the corresponding sample belongs to a particular class.
# Use the predict() method to get a list of predictions for the samples in our# test data. Then output those predictionsfrom sklearn.metrics import accuracy_score, f1_score, recall_score, confusion_matrix, precision_scoreaccuracy = accuracy_score(Y_test, YPred)recall = recall_score(Y_test, YPred, average='macro')precision = precision_score(Y_test, YPred, average='macro')f1 = f1_score(Y_test, YPred, average='macro')print(accuracy)print(recall)print(precision)print(f1)
Most of the sklearn metric function work using the same pattern. We import the function, then give it a list of the true values for our test data, and a list of the values the model predicted for our test data. The metric then outputs the value. How we interpret that value will depend on the exact problem we’re solving, the qualities of our data, and the particular metric we’re using.
Accuracy
Since this is a multiclass classification problem (“multiclass” means we have more than two options we’re choosing from), we can get a quick estimate from the accuracy_score() function, which tells us the percent of correct predictions made by the model.
# Import the accuracy_score function and use it to determine# how accurate the models predictions were for our test data
Confusion Matrix
While the accuracy score tells us a little about the model’s performance, it doesn’t tell us much.
For example, we know how often the model was correct, but we don’t know when it was wrong or why.
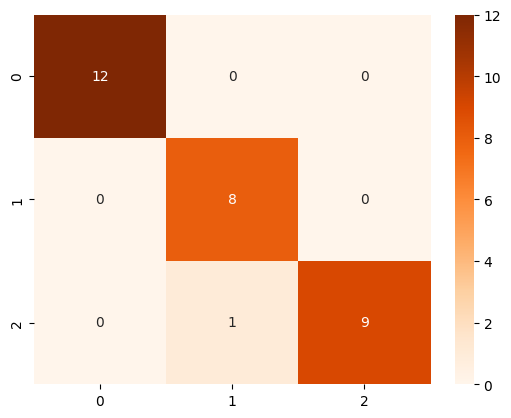
# Import the confusion_matrix function and use it to generate a confusion# matrix of our model results.cm = confusion_matrix(Y_test, YPred)cm
array([[12, 0, 0],
[ 0, 8, 0],
[ 0, 1, 9]])
Confusion Matrix Plot
It’s easier to see the results of the confusion matrix if we plot the results. One way to do this is with Seaborn’s heatmap function.
This function works a little bit differently than the others. It takes as parameters your model instance, and then options for making the chart display the way you want, and outputs a confusion matrix showing how well the model did in predicting the target values.
You’ll notice that in many cases (including this one), the numbers in the confusion matrix will be the same as the results you see from the confusion_matrix() function above, but the plot makes it easier to interpret the results.
When using the confusion matrix, you may find that the default color mapping is difficult to read. The “Blues” mapping is a popular choice.
# Create a Seaborn heatmapimport seaborn as snssns.heatmap(cm, annot=True, cmap='Oranges')
🌟 Above and Beyond 🌟
Once you’ve complted the basics, try to complete one or more of the following tasks:
See if you can get better results from your model through some data preprocessing, such as normalization.
Often, using too many features can give poor results. Can you get better performance using a subset of the features instead of all four?
Are there other ways you could visualize your model results?
from sklearn.metrics import classification_reportprint(classification_report(Y_test, YPred))